
An AI output can look completely correct and still break your pipeline. That's the uncomfortable truth most developers discover only after a bad incident in production. Surface accuracy is easy to achieve. Preserving the full intent, structure, and constraints of your prompt is much harder. AI response fidelity is more about intent preservation than surface accuracy, and that distinction matters enormously when you're building downstream systems that depend on structured data. This guide breaks down what fidelity means, how to measure it, and how to engineer your way to more reliable AI outputs.
Table of Contents
- What is AI response fidelity?
- How is fidelity evaluated in real AI systems?
- Common pitfalls and edge cases: Where AI fidelity fails
- Engineering for fidelity: Strategies to boost AI output reliability
- AI response fidelity: What most experts miss about real-world reliability
- Empower your AI projects with reliable structured data
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Fidelity goes beyond accuracy | True AI response fidelity measures if the output preserves the prompt's intent, schema, and constraints—not just correctness. |
| Multi-dimensional evaluation is vital | Surface metrics miss edge-case failures, so using several metrics together gives a clearer fidelity picture. |
| Schema and validation are crucial | For structured data, always enforce schema rules and validate or retry outputs for reliable downstream use. |
| Failure modes can be subtle | Even fluent, accurate outputs can hide intent or structure drift, so proactive safeguards are a must. |
| Engineering strategies exist | Controlling model freedom, validating output, and using fallback retries directly improve your application’s response fidelity. |
What is AI response fidelity?
Fidelity is not the same as accuracy. A model can return a factually correct statement that still violates the schema you specified, drops a required field, or reframes the intent in a way that corrupts your downstream logic. That's a fidelity failure, not a factual one.
AI response fidelity is about maintaining intent or constraints, not just correctness. Think of it as a family of overlapping concepts rather than a single metric. It covers:
- Semantic fidelity: Does the output preserve the original meaning and intent of the prompt?
- Schema fidelity: Does the output conform to the expected data structure, field names, and types?
- Constraint fidelity: Does the output respect explicit rules, limits, and formatting requirements?
- Behavioral fidelity: Does the model behave consistently across similar inputs over time?
The reason this matters for structured data for AI performance is straightforward. When you're parsing AI outputs programmatically, a paraphrased field name or a shifted meaning is just as damaging as invalid syntax. Your parser doesn't understand intent. It just reads bytes.
"Fidelity failures often occur silently. The output passes a basic validity check, but the meaning has already been lost somewhere between the prompt and the response."
Common failure modes include paraphrasing that changes key terms, output drift where the model switches to a slightly different format after several turns, and structural mismatches where the model returns the right content in the wrong location. Recognizing these patterns is the first step. Fixing broken JSON from AI is often the visible symptom of deeper fidelity problems that started at the prompt design level.

How is fidelity evaluated in real AI systems?
Measuring fidelity is harder than measuring accuracy. There is no single benchmark that captures all dimensions. Real-world evaluation requires a multi-metric approach that looks at several layers simultaneously.
Fidelity is often evaluated alongside accuracy, safety, and tone in conversational AI frameworks, which makes it a multidimensional problem by nature. Here's how each type is typically assessed in production-grade pipelines:
| Fidelity type | What it measures | Common evaluation method |
|---|---|---|
| Semantic fidelity | Meaning and intent preservation | Cosine similarity, human review |
| Schema fidelity | Field names, types, structure | Schema validation, diff tools |
| Constraint fidelity | Rule adherence, range limits | Rule-based validators, unit tests |
| Behavioral fidelity | Consistency across runs | Regression testing, A/B evaluation |
The issue with relying on just one of these is that it creates blind spots. A model that scores well on semantic similarity might still fail schema validation on 15% of outputs. A model that passes schema checks consistently might drift in meaning under multi-turn compression. You need all four lenses.
Factual consistency is also quantifiable. Benchmarking factual consistency in LLMs shows that factual consistency across LLM personas can be quantified using cosine similarity, with scores clustering around 0.8656. That number is useful as a baseline. If your pipeline is seeing significantly lower consistency, something in your prompting or schema design needs attention.
Schema matching techniques become essential at scale because manual review doesn't hold up. As your output volume increases, automated schema validation and semantic scoring need to be baked into the pipeline, not bolted on afterward.
For teams building dataset validation for AI workflows, fidelity benchmarking should be a first-class citizen in your evaluation setup, not an afterthought.
Common pitfalls and edge cases: Where AI fidelity fails
Evaluating fidelity in theory is one thing, but here are some real cases where it breaks down in practice.
The most dangerous fidelity failures are invisible ones. The output looks fine. It passes a JSON lint check. The fields are all present. But the actual values have shifted in meaning, the context has been compressed, or a required constraint has been silently dropped.
Edge cases often involve outputs that look correct but actually drift in intent or schema. Here are the most common patterns you'll encounter in real applications:
- Paraphrased field values: The model rewrites an enum value or a constrained string in its own words. Your validator accepts it, but your downstream consumer breaks.
- Context compression in multi-turn sessions: In longer conversations or chained requests, the model may compress earlier context. Critical constraints from earlier turns get dropped without warning.
- Missing optional fields that became required: A model that was fine-tuned or prompted differently may stop returning fields it previously included, breaking consumers that assumed consistency.
- Type coercion errors: The model returns ""true"
as a string instead of a booleantrue`. Schema validators that aren't strict will miss this entirely. - Structural reorganization: The model returns all the right data, but nested fields are flattened or arrays are returned as objects.
"Surface fluency is not a proxy for structural correctness. An output that reads well to a human can still destroy a data pipeline."
Multi-turn or batch-compressed outputs are particularly prone to failure. When a model is summarizing or condensing earlier context, fidelity degradation compounds. Each compression step introduces more distance from the original intent.
Pro Tip: Don't rely on readability as a quality signal for structured outputs. Set up structured output validation that checks schema conformance, type correctness, and constraint adherence as separate passes. A readable output that fails schema validation is still a broken output.
Good data preprocessing for AI workflows include validation checkpoints that catch these failures before they propagate downstream. Build the check early, and you save hours of debugging later.
Engineering for fidelity: Strategies to boost AI output reliability
So, how can you proactively prevent those failures and deliver reliable, high-fidelity AI outputs?
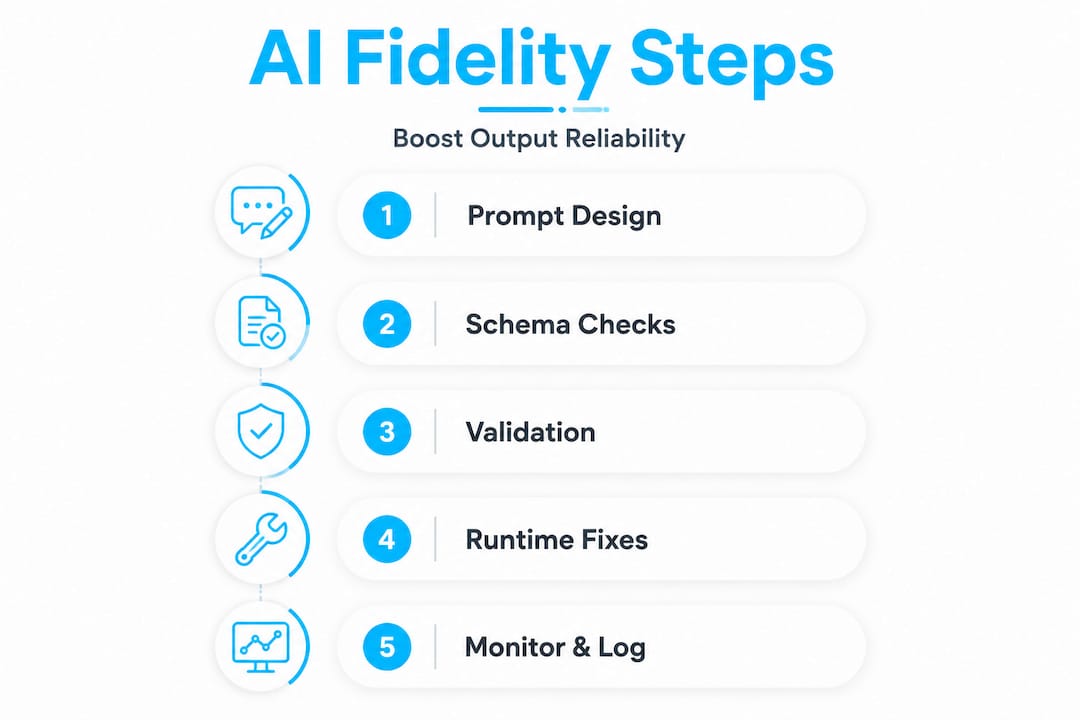
The answer is a combination of upfront design and runtime verification. You can't rely on a single prompt to guarantee fidelity. You need a layered approach that controls model behavior, validates output at multiple levels, and retries intelligently when something fails.
For structured outputs, use strong schema constraints, prompt design, and validate-retry for best fidelity. Here is a practical, ordered strategy:
- Embed schema in the prompt explicitly. Don't just describe the output format. Include the actual schema or a concrete example. Models respond better to explicit structure than to natural language descriptions of structure.
- Constrain model freedom. Use temperature settings near zero for structured tasks. Reduce token limits to prevent the model from padding outputs with explanatory text that breaks parsers.
- Use schema-native output modes where available. Many LLM APIs now support JSON mode or function-calling mode. Use these over free-text responses for any structured data workflow.
- Validate before you consume. Run every output through a schema validator before it touches downstream logic. Treat unvalidated AI output the same way you'd treat unvalidated user input.
- Implement a retry loop with targeted correction. If validation fails, feed the error back into the model with specific instructions: "The previous response was missing the
statusfield. Regenerate with all required fields present." Targeted retries work significantly better than blind retries. - Log and audit fidelity failures. Track which fields fail most often, under which prompt conditions, and at what frequency. This data drives continuous improvement in your prompt design.
Degrees of prompt fidelity can be quantitatively assessed, ranging from pure model inference to full constraint verification. The practical implication is that you can score your prompt designs before deploying them. A prompt that achieves 0.95 fidelity under testing conditions will behave very differently in production than one that scores 0.6.
| Strategy | Fidelity impact | Implementation effort |
|---|---|---|
| Schema-in-prompt design | High | Low |
| JSON/function-calling mode | High | Low |
| Temperature near zero | Medium | Very low |
| Validate-and-retry loop | Very high | Medium |
| Failure logging and feedback | Long-term high | Medium |
Pro Tip: Build your retry logic to include the specific validation error, not just a generic "try again" instruction. Telling the model exactly what failed dramatically improves first-retry success rates for schema-related errors.
Fixing and validating AI output at runtime is not a workaround. It's a mature engineering practice. The best pipelines treat LLM outputs as inherently unreliable until proven otherwise, and validate accordingly.
For teams looking to strengthen their overall data strategy, following proven dataset structuring steps helps ensure that the upstream data feeding your models is also supporting higher-fidelity outputs at inference time.
AI response fidelity: What most experts miss about real-world reliability
Most conversations about AI fidelity focus on prompt engineering. Craft a better prompt, get a better output. That's true, but it's incomplete.
The deeper issue is that even a well-crafted prompt will degrade over time. Models are updated. Context windows are reused in ways you didn't anticipate. Edge cases accumulate. The production environment introduces variables that testing never captures fully. Fidelity is not a one-time achievement. It's an ongoing maintenance problem.
Here's what we've learned from working with real AI pipelines: intent loss doesn't usually show up as a dramatic failure. It shows up as a slow drift. Fields start returning subtly different values. Enums get paraphrased. Nested structures flatten. Each change is small enough to pass a casual review. Together, they corrupt the data quality of your entire pipeline over weeks.
The teams that handle this well do one thing differently. They treat fidelity as a runtime property, not a design property. They instrument their pipelines to catch drift early, using the same rigor they'd apply to catching performance regressions in application code. Production data fidelity lessons from real deployments show that feedback loops and explicit validation matter more than initial prompt quality over any extended time horizon.
The uncomfortable truth is that surface metrics give false confidence. A model that returns 98% schema-valid outputs is still breaking your pipeline 2% of the time if you're running at scale. At 100,000 requests per day, that's 2,000 broken outputs hitting your consumers. Fidelity has to be treated as a reliability engineering problem, not just an AI quality problem.
Invest early in validation infrastructure. Build retry logic before you need it. Log every fidelity failure. The cost of that upfront investment is a fraction of the cost of debugging a degraded pipeline six months into production.
Empower your AI projects with reliable structured data
Broken outputs are a constant in LLM-powered workflows. Missing fields, schema drift, invalid escaping, truncated responses, type mismatches. These aren't edge cases. They're the everyday reality of working with AI-generated structured data at any real scale.
datatool.dev for reliable AI JSON output is built specifically for this problem. It handles broken JSON, wrapped responses, partial objects, and schema violations from real LLM outputs, giving you a practical tool to repair and validate before bad data reaches your pipeline. Whether you're debugging a single malformed response or building automated validation into a production system, the tools are designed to reduce the friction between raw AI output and clean, reliable structured data. Start validating your outputs today.
Frequently asked questions
How is AI response fidelity different from accuracy?
Fidelity measures if AI preserves the intent and constraints of your prompt, while accuracy focuses on factual correctness or word overlap. AI response fidelity reframes evaluation beyond accuracy, focusing on intent and communicative purpose.
What causes fidelity failures in AI-generated structured data?
Failures often happen when outputs look correct but the underlying schema or intent is changed due to paraphrasing or context loss. Semantic fidelity notes failures where outputs can seem correct but lose the key intended meaning.
Can fidelity be measured quantitatively in structured outputs?
Yes, using benchmarks like prompt fidelity scores or schema validation pass rates. Prompt fidelity, ranging from 0 to 1, measures how much of a prompt's intent is executed. LLMs can also be benchmarked for factual consistency using sentence embeddings and cosine similarity.
What practical steps can developers take to improve AI response fidelity?
Use strong schema constraints, validate and retry outputs, and reduce model freedom to prevent errors from reaching your data pipeline. A structured-output pipeline recommends schema constraints, validation, and retries for consistently high fidelity.