
Passing JSON parsing is not the same as producing correct output. Many AI developers treat a successful parse as a green light, only to discover downstream failures caused by wrong field values, hallucinated IDs, or silently truncated objects. These errors slip through the most common validation checks and surface later, in production, where they are expensive to fix. This guide walks through a layered, practical approach to detecting AI output errors at every level, from basic syntax to semantic correctness, so you can build pipelines you actually trust.
Table of Contents
- Why valid JSON isn't enough: The three layers of error detection
- Understanding common sources of AI output errors
- Frameworks and metrics for robust error detection
- Automating validation: Detection, retry loops, and logging
- What most detection frameworks miss: The ground-truth paradox
- Automate error detection with specialized tools
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Layered validation | Combining parse, schema, and semantic checks is necessary for reliable AI output error detection. |
| Beyond provider tools | Provider constraints reduce errors but cannot replace application-side semantic validation. |
| Benchmark the right way | Field-level value accuracy and trust scores matter far more than JSON pass rates. |
| Automated retry loops | Fed-back validation and systematic error logging make detection and correction scalable. |
| Trust your ground truth | Detection is only as reliable as the quality of your reference benchmarks and ground truth data. |
Why valid JSON isn't enough: The three layers of error detection
The first instinct when validating AI output is to run a JSON parser. If it parses, it passes. This assumption is wrong, and it causes real problems at scale.
Reliable detection requires three distinct layers. Each one catches a different class of error. Skipping any layer means errors will reach your application undetected.
Layer 1: Syntactic validation checks whether the output is parseable JSON. This catches missing brackets, unescaped characters, trailing commas, and other format-level issues. It is necessary but not sufficient.
Layer 2: Schema validation checks whether the parsed output matches the expected structure. Are all required fields present? Are types correct? Do enum values fall within allowed ranges? A model can return perfectly parseable JSON with the wrong fields entirely, and syntactic validation will not catch it.
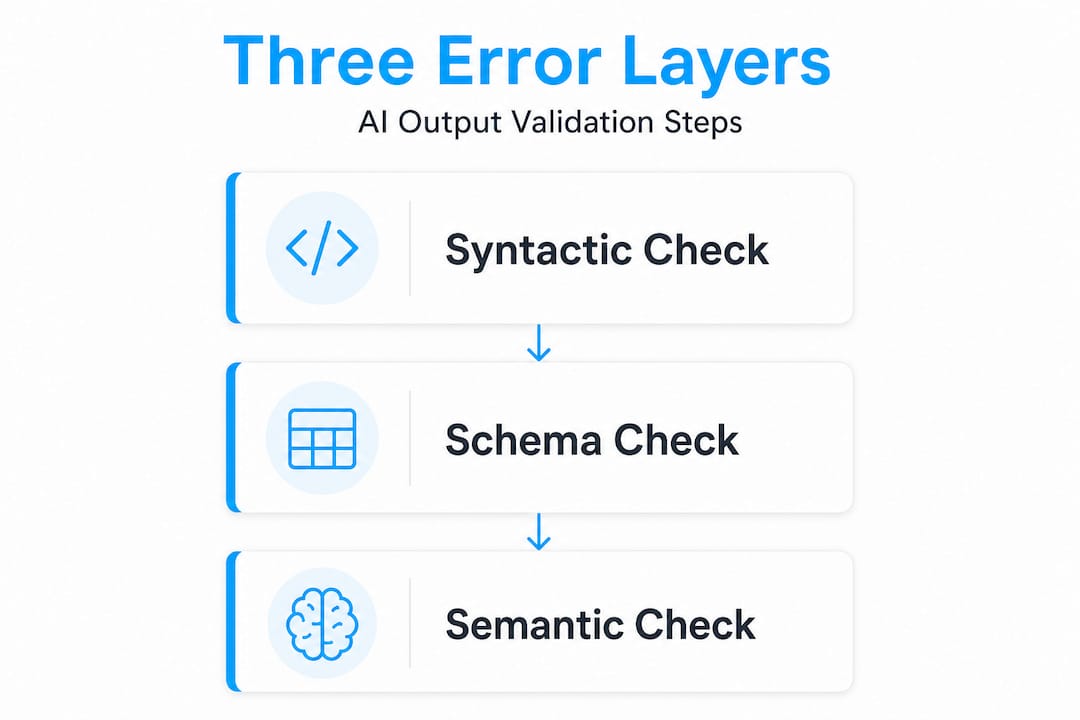
Layer 3: Semantic validation checks whether field values are actually correct given the business context. Is the date in the future when it should be historical? Is the product ID a real one? Does the extracted price match the source text? This is where most pipelines fail. As layered validation research confirms, models often pass parse and schema checks while failing on value correctness entirely.
Here is a quick comparison of what each layer catches:
| Layer | Check type | Typical errors caught |
|---|---|---|
| Syntactic | Parse/format | Broken brackets, bad escaping, truncation |
| Schema | Structure/type | Missing fields, wrong types, invalid enums |
| Semantic | Value correctness | Wrong values, hallucinated IDs, business rule violations |
"Structured output mechanisms reduce structural failures, but application-side validation is still required for semantic correctness and edge cases."
Errors missed by each layer include:
- Syntactic only: Wrong field names, incorrect types, hallucinated values
- Schema only: Plausible but factually wrong values, out-of-range numbers, mismatched references
- Semantic only: Format issues that downstream parsers cannot handle
Start fixing broken JSON at the syntactic layer, but never stop there.
Understanding common sources of AI output errors
Once you accept that three layers exist, the next question is: where do errors actually come from? The answer is more varied than most teams expect.
Syntactic errors are the most visible. Truncated outputs, broken escape sequences, and partial objects are common when models hit token limits or when output formatting instructions are ambiguous. These are the easiest to detect and fix.

Schema errors occur when a model returns a valid JSON object that does not match the expected schema. A field named "user_idmight appear asuserIdorid`. A required field might be missing entirely. These happen frequently when prompts are vague or when the model drifts from the schema across a long context window.
Semantic errors are the hardest to catch. The model returns a value that looks correct but is not. A date field contains a plausible but wrong date. A product description is fabricated. A numeric field contains an outlier that passes range checks but is statistically impossible. These require domain knowledge to detect.
Refusals happen when the model declines to generate a structured response, often returning an explanation in plain text instead of JSON. Provider-level structured output mechanisms reduce structural failures, but they do not eliminate refusals or guarantee semantic correctness. Always check provider metadata.
Hallucinated fields are a specific and frustrating failure mode. The model invents fields that were not in the schema, sometimes with plausible-sounding names. These pass syntactic validation and can even pass loose schema validation if your validator does not enforce strict mode.
Here is a breakdown of error types and their origins:
| Error type | Primary source | Detection layer |
|---|---|---|
| Truncation | Token limit exceeded | Syntactic |
| Missing fields | Schema drift, vague prompt | Schema |
| Wrong enum value | Model uncertainty | Schema/Semantic |
| Hallucinated ID | Model fabrication | Semantic |
| Refusal | Safety filter, ambiguous input | Provider metadata |
| Numeric outlier | Extraction error | Semantic |
Practical signs that an AI output is failing silently:
- Unexpected
nullvalues in fields that should always be populated - Numeric values that are orders of magnitude off from expected ranges
- Enum values that do not match your allowed list
- Fields present in the output that are not in your schema
- Provider stop reason indicating truncation or refusal
Pro Tip: Always inspect provider metadata alongside the output itself. Stop reasons, finish reasons, and token usage fields often reveal truncation or refusal before you even parse the JSON body.
Frameworks and metrics for robust error detection
Knowing the error types is one thing. Measuring them systematically is another. Most teams track JSON pass rate and stop there. This is a mistake.
Field-level trust scoring provides a more reliable signal. Instead of treating a document as pass or fail, you score each field independently. A document might have high confidence on most fields but low confidence on one extracted date. That field-level signal tells you exactly where to focus review effort.
The key metrics to track in any structured output pipeline are:
- Schema pass rate: Percentage of outputs that conform to the expected schema
- JSON pass rate: Percentage of outputs that parse successfully
- Value accuracy: Percentage of field values that match ground truth
- Per-document trust score: Aggregate confidence across all fields in a single output
- Field-level error rate: Error frequency broken down by individual field
The gap between JSON pass rate and value accuracy is where teams get burned. Structured output benchmarking consistently shows that models can achieve JSON pass rates above 95% while value accuracy sits 20 to 30 percentage points lower. A pipeline that reports 97% JSON pass rate might actually be delivering wrong values in nearly a third of its outputs.
This is not a theoretical concern. In extraction pipelines, a 30-point gap between parse success and value accuracy means roughly one in three documents contains at least one incorrect field value. At production scale, that is a significant data quality problem.
The solution is to build benchmarks that separate these metrics explicitly. Do not combine them into a single score. Track them independently so you can see when a model change improves parsing but degrades accuracy, or vice versa.
Pro Tip: Use curated, hand-verified benchmark suites rather than relying on public datasets. Public benchmarks often contain label noise that makes your metrics look better than they are. A small, clean benchmark is more informative than a large, noisy one.
Statistical callout: Benchmarking data shows JSON pass rates frequently exceed 95%, while leaf-value extraction accuracy can be 20 to 30 points lower on the same outputs. That gap represents real errors reaching your application.
Automating validation: Detection, retry loops, and logging
Metrics and frameworks are only useful if they feed into an automated pipeline. Manual review does not scale. You need a system that detects errors, logs them, and attempts correction without human intervention.
Here is the core loop for automated validation in production:
- Run syntactic validation. Parse the output. If parsing fails, log the raw output with the failure reason and proceed to retry.
- Run schema validation. Check required fields, types, and enum values. Log any violations with field-level detail.
- Run semantic validation. Apply business rules, range checks, and cross-field consistency checks. Log violations with the specific rule that failed.
- Return error context to the model. If any layer fails, construct a correction prompt that includes the original output and a precise description of what failed. Do not just retry with the same prompt.
- Retry with correction context. Send the correction prompt and validate the new output through all three layers again.
- Log all attempts. Store every raw output, every validation result, and every retry. This data is essential for debugging and for improving your prompts over time.
Automated retry loops that feed validation errors back to the model are significantly more effective than blind retries. A blind retry often produces the same error. A correction prompt that says "the field event_date must be in ISO 8601 format; your output contained March 5th, 2026" gives the model the information it needs to fix the specific problem.
The distinction between syntactic and semantic failures matters in retry loops. Syntactic failures are often caused by formatting issues that a direct instruction can fix. Semantic failures may require additional context, a different prompt strategy, or escalation to human review. Treat them differently in your retry logic.
Storing failing outputs is not optional. It is one of the highest-value practices in any AI pipeline. Raw failing outputs let you identify patterns, cluster similar errors, and make targeted prompt improvements. Without them, you are debugging blind.
Implementing schema and parse validations as discrete, logged steps also creates an audit trail. When a downstream system reports bad data, you can trace exactly which validation layer failed, when, and what the model returned.
Pro Tip: Log each failed layer separately with a precise error code. Do not collapse all failures into a single "validation error" label. Granular logs make root cause analysis dramatically faster and support compliance auditing when required.
What most detection frameworks miss: The ground-truth paradox
Here is the part most guides skip entirely. You can build a perfect three-layer validation system, implement field-level trust scoring, and run automated retry loops, and still end up with a misleading picture of your model's actual performance.
The reason is ground truth quality.
Every benchmark, every accuracy metric, and every semantic validator ultimately depends on a reference. If that reference is wrong, your detection pipeline will report false confidence. You will think your model is performing well when it is not, or flag correct outputs as errors.
This is not a hypothetical edge case. Public structured output benchmarks have been found to contain incorrect and inconsistent ground-truth labels. When you evaluate your model against a noisy benchmark, you are measuring noise as much as you are measuring model quality.
The practical implication is uncomfortable: your detection pipeline is only as reliable as the ground truth it references. A 95% accuracy score against a benchmark with 5% label errors tells you almost nothing meaningful.
The conventional wisdom is to use more data. More examples, more diversity, bigger benchmarks. But quantity does not fix quality. A thousand noisy examples are worse than a hundred carefully verified ones for the purpose of detection and evaluation.
Our recommendation is to invest in custom benchmark curation before you invest in more complex detection methods. Build a small set of verified, domain-specific examples that you personally trust. Use that as your primary evaluation set. Supplement with public benchmarks only after you understand their error rates.
This is especially true for semantic validation. Business rules are domain-specific. Public benchmarks do not know your data. The only ground truth that matters for your pipeline is the one you built and verified yourself.
Automate error detection with specialized tools
The framework in this guide gives you a clear path: validate in layers, track the right metrics, run correction loops, and maintain clean ground truth. That is the right approach. But building all of it from scratch takes time.
datatool.dev is built specifically for AI developers dealing with malformed structured outputs. It handles the repair and validation layer directly, covering broken JSON, wrapped responses, partial objects, invalid escaping, truncation artifacts, and schema drift. You paste the output. You get valid, schema-conformant JSON back. The platform is designed for real-world LLM output, not idealized examples.
If you want to repair structured JSON AI outputs without building a custom parser from scratch, datatool.dev gives you that capability immediately. It fits into your existing pipeline as a validation and repair step, reducing the manual troubleshooting that slows down iteration. Less time debugging malformed output means more time improving your models and prompts.
Frequently asked questions
How do I know if my AI output needs more than just JSON validation?
If your application depends on data accuracy and business rules, JSON validation alone is insufficient. Valid JSON is not sufficient: you must also verify schema constraints and domain semantics for reliable production behavior.
What are some signs of hidden errors in AI-generated structured data?
Look for mismatched field values, illegal enum values, suspicious nulls, or outputs flagged as truncated or refused by provider metadata. Refusals and truncation can cause non-conformance even when using provider-level structured output features.
Is there a metric better than JSON pass rate for evaluating AI output quality?
Yes. Value accuracy at the field level and per-document trust scores give a more reliable picture. JSON pass rates can exceed 95% while leaf-value extraction accuracy is substantially lower on the same outputs.
How can I reduce repeated AI output errors in production?
Implement automated retry loops that validate, log, and feed error context back to the model for correction. Automated retry loops that include specific failure descriptions are significantly more effective than blind retries.
Why do some benchmarks fail to reveal all AI output errors?
Some public benchmarks contain noisy or incorrect ground-truth labels, which can make your model appear more accurate than it is. Several public benchmarks include inconsistent ground-truth outputs, which is why curated, domain-specific evaluation sets are more reliable for production use.