
Your AI pipeline generates a structured JSON payload for a business-critical workflow. It looks fine at first glance. Then, three hours later, a downstream service crashes because one field returned a string where an integer was expected, and another field was missing entirely. No syntax error. No exception thrown. Just silent corruption moving through your system. This is the core problem with AI-generated structured data: the model doesn't fail loudly. It fails quietly, and your tests need to catch that before production does.
Table of Contents
- Understanding the testing challenge with AI-generated structured data
- Setting up your testing environment: Tools, schemas, and requirements
- How to write effective unit tests for AI-generated data contracts
- Handling edge cases, regression, and security with validation layers
- Ensuring reproducibility and CI reliability for AI-powered tests
- Why contract-based testing is the right approach for AI-generated data
- Tools for seamless validation and reliability
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Focus on deterministic tests | Target the layers that transform and validate model output, not the AI's raw response. |
| Validate structure and schema | Check syntax and contract compliance before trusting AI-generated data downstream. |
| Use property-based testing | Probe edge cases and rare failures by testing invariants across wide output ranges. |
| Layer security and regression checks | Detect structural and security edge cases with multi-step validation flows. |
| Cache and version test data | Keep tests repeatable and reliable by storing and controlling generated datasets. |
Understanding the testing challenge with AI-generated structured data
Traditional unit testing assumes predictable inputs and outputs. You write a function, define its expected behavior, and assert against exact results. AI-generated data breaks that model immediately.
The key insight is that testing AI model output contract requires separating two fundamentally different layers. One layer is deterministic. The other is not.
Deterministic layers include:
- Prompt construction logic
- Response parsing and deserialization
- Schema validation functions
- Data transformation pipelines
- Error handling and fallback logic
Nondeterministic layers include:
- The raw model output itself
- Token sampling and temperature effects
- Model version drift over time
As unit testing LLM-powered code confirms, unit tests should primarily cover the deterministic layers and validate the structured contract of the model output, not the raw response. You cannot reliably assert that a model will always return the exact same string. You can assert that whatever it returns must conform to a defined schema with specific types, required fields, and value constraints.
| Layer | Type | Testable with unit tests? |
|---|---|---|
| Prompt construction | Deterministic | Yes, fully |
| Response parsing | Deterministic | Yes, fully |
| Schema validation | Deterministic | Yes, fully |
| Raw model output | Nondeterministic | No, use contract checks |
| Transformation logic | Deterministic | Yes, fully |
"Treat AI output as a data contract. Define the schema, the invariants, and the constraints. Test everything around the model, and validate the contract at the boundary."
This framing changes everything. Your tests stop asking "did the model say the right thing?" and start asking "does the output satisfy the contract we defined?" That question is always answerable with a deterministic test.
Setting up your testing environment: Tools, schemas, and requirements
Now that you've mapped out where deterministic logic lives, it's time to prepare the right environment and tools for unit testing.
Start by defining your output contract explicitly. A contract for AI-generated structured data typically includes:
- Required fields: which keys must always be present
- Type constraints: integer, string, boolean, array, and so on
- Value ranges: minimum and maximum values, allowed enum values
- Structural invariants: nesting rules, array length limits, nullable fields
Once the contract is written, choose your schema validation tools carefully. For JSON-based AI outputs, JSON Schema (with libraries like "jsonschemafor Python orajv` for JavaScript) is the standard starting point. For typed languages, Pydantic (Python) and Zod (TypeScript) provide runtime schema enforcement with strong ergonomics.
As layered validation for structured outputs demonstrates, you should check both syntax (parseable JSON) and schema/constraints (type, required fields, ranges) before the data is used downstream. These are two separate checks, and both must pass.

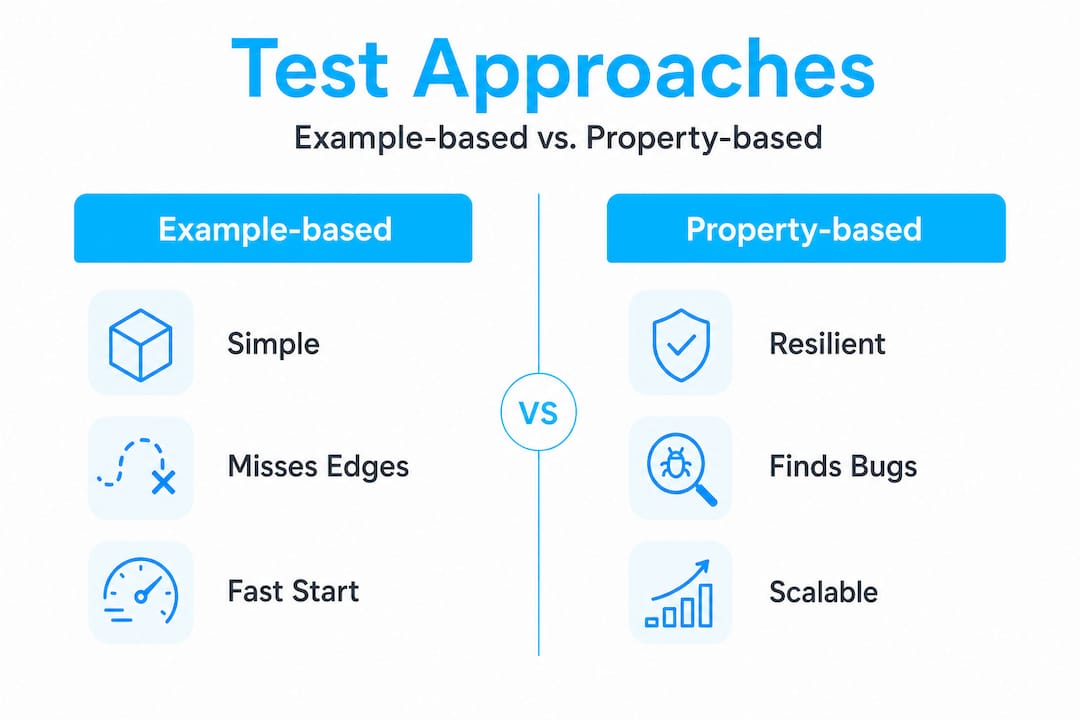
Example-based vs. property-based testing for AI data:
| Approach | Strengths | Weaknesses |
|---|---|---|
| Example-based | Simple to write, easy to read | Misses edge cases, brittle for AI outputs |
| Property-based | Explores large input spaces, catches edge cases | Requires more setup, harder to debug failures |
For AI-generated data, property-based testing is the stronger long-term investment. It lets you define invariants ("the user_id field must always be a positive integer") and then automatically generate thousands of test cases to probe those invariants.
Pro Tip: Version and cache your generated test datasets. Store them as fixtures in your repository. This gives you a stable baseline for regression testing without re-calling the model on every test run.
Your testing environment should also include a clear separation between unit tests (which mock model calls) and integration tests (which may call the model directly). Keep unit tests fast and deterministic. Reserve live model calls for integration and end-to-end suites.
How to write effective unit tests for AI-generated data contracts
With your tools and schemas ready, here's how to put them into action with robust test authorship and execution.
Step-by-step unit test implementation:
-
Define your schema as code. Use Pydantic, Zod, JSON Schema, or a similar library. The schema is your ground truth. Every test references it.
-
Write a parser unit test. Feed your parsing function a raw model response string (stored as a fixture). Assert that it produces a valid Python dict or typed object without raising exceptions.
-
Write a schema validation unit test. Pass the parsed output through your schema validator. Assert that valid fixtures pass and that intentionally malformed fixtures fail with the correct error type.
-
Add property-based tests for invariants. Use Hypothesis (Python) or fast-check (JavaScript) to generate hundreds of variations. Define properties like "the
pricefield is always a float greater than zero" and let the framework find counterexamples. -
Write negative tests. Explicitly test that your validation pipeline rejects truncated JSON, missing required fields, wrong types, and out-of-range values. These are the cases your AI will eventually produce.
-
Assert on structure, not exact values. For AI outputs, property-based testing validates invariants over large spaces of possible generated inputs and outputs, which is especially suited to catching edge cases in AI-produced structured data. Exact string matches will fail on model updates. Structural assertions will not.
-
Test your transformation pipeline. After validation, data often goes through normalization or enrichment. Unit test each transformation step independently with fixed inputs.
Statistic callout: Research on ChatGPT-generated unit tests found that unit testing frameworks for LLM-generated code should avoid brittle exact-string assertions and instead use semantic or structural criteria aligned to the contract you care about. Exact matches break on model updates. Contracts don't.
Semantic assertions are the practical answer here. Instead of asserting output["status"] == "active", assert output["status"] in VALID_STATUS_VALUES. Instead of asserting an exact timestamp string, assert that the value is a valid ISO 8601 datetime. This approach survives model drift and minor output variation.
One more critical point: a significant portion of LLM-generated assertions have been found incorrect without human review. Don't let the model write your test assertions without verification. Write them yourself, grounded in the actual contract requirements.
When you're fixing broken JSON from a model response before it even reaches your validator, you need that repair step to be its own tested, deterministic function. Test it in isolation. Don't bundle repair logic with validation logic.
Handling edge cases, regression, and security with validation layers
Every robust testing strategy must plan for the unexpected. Here's how to tackle the toughest cases and ensure durable quality.
Edge cases in AI-generated structured data fall into three categories:
Structural edge cases:
- Missing required fields
- Extra unexpected fields
- Wrong data types (string where integer expected)
- Null values in non-nullable fields
- Empty arrays or objects where content is required
- Deeply nested structures that exceed expected depth
Content edge cases:
- Values at boundary limits (zero, negative numbers, very large integers)
- Empty strings in required text fields
- Unicode characters and special characters in string fields
- Extremely long strings that exceed field length limits
Security-relevant edge cases:
- XSS payloads embedded in string fields
- SQL injection strings in text fields
- Path traversal strings in filename fields
- Unexpected HTML or script tags in data fields
As structured-output validation makes clear, edge cases for AI-generated data should include both structural corner cases (missing or extra fields, wrong types, boundary values) and security-relevant content embedded into fields that are supposed to be purely data.
Your defensive validation layers should be stacked in order:
- Syntax check: Is the response valid JSON at all?
- Schema check: Does it match the required structure and types?
- Content check: Are the values within acceptable ranges and formats?
- Security check: Do any fields contain dangerous content?
"Schema validation should reject both syntactically invalid responses and semantically wrong-but-JSON-valid outputs. Use defense-in-depth with separate structure versus content checks." Output validation for AI agents
Regression testing is equally important. When a model update causes a new failure pattern, capture that exact failing payload as a fixture and add it to your test suite permanently. This builds a library of known failure modes over time. Your test suite gets smarter with every incident.
Rule-based checks for sensitive fields should be explicit and strict. If a field should contain a product name, validate that it matches a pattern like [A-Za-z0-9 \-]{1,100}. Don't rely on the model to self-constrain. It won't.
Ensuring reproducibility and CI reliability for AI-powered tests
After your tests are robust and layered, ensure they actually work reliably in CI and real-world repeatable scenarios.
Reproducibility is the silent killer of AI test suites. If your tests call the model on every run, you get nondeterministic results, flaky CI pipelines, and tests that pass locally but fail in your build system. The fix is straightforward but requires discipline.
Key practices for reproducible AI tests:
- Cache model outputs as fixtures. Generate a representative set of model responses once, store them as JSON files in your test fixtures directory, and use them for all unit test runs.
- Version your fixtures. When the model changes or your prompt changes, generate a new fixture set and version it alongside your code. This gives you a clear audit trail.
- Mock model calls in unit tests. Your unit tests should never make live API calls. Use mocking libraries (
unittest.mockin Python,jest.mockin JavaScript) to return fixture data instead. - Separate fixture generation from test execution. Have a dedicated script or CI job that regenerates fixtures periodically or on demand, not on every test run.
- Use deterministic seeds where possible. Some model APIs support a seed parameter for reproducibility. Use it during fixture generation.
As smart test data generation confirms, when generating AI or synthetic test datasets, you should cache and version generated datasets to keep tests reproducible and avoid re-calling the model or regeneration nondeterminism every run.
Pro Tip: Add a CI check that fails if any unit test makes an outbound network call. This enforces the mocking discipline automatically and prevents accidental live model calls from slipping into your unit test suite.
The test reproducibility and caching workflow also protects you from cost overruns. Live model API calls in CI can become expensive fast, especially if your test suite runs on every pull request. Cached fixtures cost nothing to run.
Keep your fixture library organized by model version and prompt version. When you update either, generate new fixtures and run your full test suite against them before merging. This is your regression gate.
Why contract-based testing is the right approach for AI-generated data
Here's the honest take after working through real-world AI output failures at scale: most teams waste time trying to make AI outputs more predictable, when they should be making their validation pipelines more robust.
The contract-testing mindset fixes this. When you treat AI output as a data contract, you stop caring whether the model "behaves correctly" in some abstract sense. You only care whether the output satisfies the contract. That's a much more tractable problem.
The mistake we see most often is teams that validate syntax and nothing else. They check that the response is valid JSON and move on. This is insufficient. A robust unit-testing strategy for AI-generated structured data is contract testing: treat the AI output as a data contract (schema plus invariants), and test the validation and transformation pipeline deterministically with strict parse and schema checks and targeted invariants. Then use property-based testing to explore long-tail edge cases.
Syntactic validity is the floor, not the ceiling. A JSON object can be perfectly parseable and completely wrong. The order_total field can be negative. The user_id can be zero. The status field can contain a value your downstream system has never seen. All of these are valid JSON. None of them are valid data.
The teams that get this right share a few habits. They define contracts before they write prompts. They treat every model update as a potential contract violation until proven otherwise. They layer their checks and never skip a layer because "the model is usually fine." And they cache aggressively, because reproducibility is not optional in a professional CI pipeline.
The uncomfortable truth is that raw AI output should never be trusted blindly, regardless of how good the model is. The model hallucinates. It drifts. It surprises you at the worst possible moment. Your contract is the only thing standing between that surprise and your production system.
Tools for seamless validation and reliability
For those seeking reliable, ready-to-use solutions, explore tools designed to make unit testing and validation simple, even for challenging AI-generated data.
datatool.dev is built specifically for the problems this article covers. It handles the full range of real-world malformed AI output: broken JSON, wrapped responses, partial objects, invalid escaping, truncation, and schema drift. Instead of writing custom repair logic for every edge case your model throws at you, you get a focused platform for fixing and validating AI data that keeps your workflow moving. Paste messy JSON. Get valid JSON back. Run your schema checks. Ship with confidence. The goal is to keep your team focused on building quality systems, not chasing elusive parsing bugs at 2 AM.
Frequently asked questions
Should I unit test nondeterministic AI model outputs directly?
It's best to unit test deterministic layers and validate the AI output contract, not the raw nondeterministic response. As confirmed by unit testing LLM-powered code, unit tests should primarily cover deterministic layers and validate the structured contract of the model output.
How do I handle edge cases in schema validation for AI-generated data?
Catch edge cases by validating structure, content, and security before using the data downstream. Structured-output validation confirms that edge cases for AI-generated data should include both structural corner cases and security-relevant content embedded in data fields.
What is property-based testing and why is it good for AI outputs?
Property-based testing checks invariants across large spaces of possible outputs, surfacing issues that simple example tests miss. It is especially suited to catching edge cases in AI-produced structured data where exact matches are too brittle to be reliable.
How can I make AI test data reproducible for CI?
Cache and version datasets so you don't have to regenerate them on every run, and keep tests deterministic by mocking model calls. Caching generated datasets is the standard approach to avoiding model nondeterminism in your CI pipeline.