
Getting AI-generated structured data into production without a pre-production AI output validation setup is how silent failures happen. The model returns broken JSON. A confidence score sits outside its allowed range. A required field is missing entirely. None of these errors throw an exception. They just propagate downstream until something breaks in a way that's hard to trace. This guide walks you through the exact components, steps, and advanced techniques you need to build a validation pipeline that catches failures before they reach production.
Table of Contents
- Key takeaways
- Pre-production AI output validation setup: the prerequisites
- Building layered validation step by step
- Advanced validation: councils, human review, and audit trails
- Common mistakes and how to avoid them
- My take on validation as a continuous practice
- Fix broken AI output before it reaches production
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Use three-layer contracts | Define input, output, and error contracts before writing a single validation rule. |
| Add semantic checks | Structural correctness alone does not catch logical errors like invalid category IDs or out-of-range scores. |
| Scale validation by risk | High-risk AI systems need formal inspection; low-risk decision-support tools need lighter checks. |
| Avoid confirmation bias | Chain-of-Validation validators must run independently without seeing the baseline output first. |
| Treat validation as continuous | Standards defined in development should become live enforcement rules in production, not a one-time gate. |
Pre-production AI output validation setup: the prerequisites
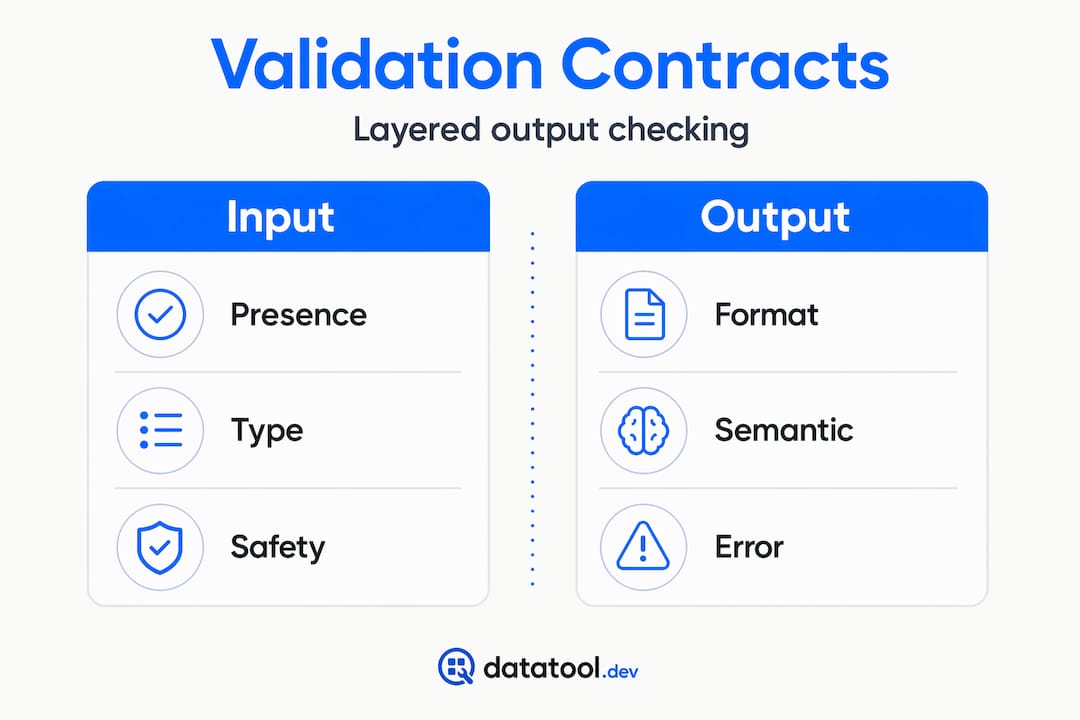
Before you write a single validation rule, you need three things defined: an input contract, an output contract, and an error contract. These three-layer validation contracts form the backbone of any reliable pre-production AI testing pipeline.
Here is what each layer covers:
- Input contract: Specifies what the model is allowed to receive. Field presence, data types, length limits. A social media post field capped at 280 characters is a classic example. Workflow contracts catch failures like this in under 15 minutes of setup.
- Output contract: Defines what a valid response looks like. JSON schema, required fields, allowed value ranges. If your model returns a confidence score, the output contract specifies it must fall between 0.0 and 1.0.
- Error contract: Determines what happens when validation fails. Does the pipeline retry with a revised prompt? Does it route to a Slack alert? Does it halt? Defining this upfront prevents cascading failures.
Beyond syntax, you also need a policy file. This is a machine-readable set of rules that covers compliance and safety checks. Think of it as the semantic layer your schema parser cannot handle on its own. For example, a policy rule might flag any output where a product category ID does not appear in your approved catalog.
| Contract type | What it validates | Who configures it |
|---|---|---|
| Input contract | Field presence, types, length limits | Data engineer |
| Output contract | Schema, value ranges, required keys | AI developer |
| Error contract | Retry logic, alert routing, halt conditions | Platform/ops team |
| Policy file | Compliance rules, semantic safety checks | Compliance + AI developer |
Building layered validation step by step
With your contracts defined, you build the actual validation stack. Here is the sequence that works in practice.
-
Run input validation first. Check that every required field is present and correctly typed before the prompt is sent to the model. An email field should match a regex pattern. A user ID should be an integer, not a string. Catching bad inputs early saves you from debugging confusing model outputs.
-
Use a structured output parser. Pass the model response through a JSON schema validator immediately after generation. If the output fails schema checks, the parser triggers a retry with a corrected prompt. Structured output parsers combined with semantic validation nodes create a deterministic chain that retries on format errors automatically.
-
Add a semantic validation layer. Schema compliance does not mean the output makes sense. Structural correctness alone does not guarantee logical validity. You need code that checks whether a confidence score is within its allowed range, whether a returned category ID exists in your lookup table, and whether numeric fields are within expected bounds.
-
Wire up your error contract. When validation fails, the pipeline should not go silent. Route failures to an error path with a notification. Workflow contracts that explicitly route failures to error paths prevent the silent cascading errors that are hardest to debug.
-
Test the whole chain with injected failures. Before promoting to production, deliberately send malformed inputs and truncated outputs through the pipeline. Verify that each failure routes to the correct handler.
Here is a concrete example of what a missing semantic check looks like and how to fix it:
"``python
BROKEN: schema passes, but semantic check is missing
def validate_output(response: dict) -> bool: # Only checks structure — category_id could be anything return "category_id" in response and "confidence" in response
FIX: add semantic validation
VALID_CATEGORIES = {101, 102, 103, 204}
def validate_output(response: dict) -> bool: if "category_id" not in response or "confidence" not in response: return False if response["category_id"] not in VALID_CATEGORIES: raise ValueError(f"Invalid category_id: {response['category_id']}") if not (0.0 <= response["confidence"] <= 1.0): raise ValueError(f"Confidence out of range: {response['confidence']}") return True
The first version lets a hallucinated category ID pass silently. The second version catches it and raises a traceable error.

**Pro Tip:** *A [fixed-prompt validation stack](https://promptnox.com/blog/prompt-validation-reliable-high-quality-ai-outputs) that combines lexical triage, semantic verification, and human review can cut manual corrections by nearly 50% compared to ad-hoc validation methods.*
## Advanced validation: councils, human review, and audit trails
Once your baseline validation pipeline is stable, these techniques add the next tier of reliability.
**Multi-model council certification** runs the AI output through four independent reviewer models in parallel. Each model scores the output, and [synthetic transparency scoring](https://pilotprotocol.network/blog/agent-communication-security-best-practices) below a threshold of 9 out of 10 triggers an automatic fail that no human can override. This removes single-model blind spots from your certification process.
**Human-in-the-loop review** is not optional for high-risk outputs. [HITL review works best](https://oorbyte.com/how-to-build-a-pre-launch-ai-output-audit-pipeline-for-brand) when paired with layered automated validation, not as a replacement for it. Route ambiguous outputs and edge cases to a human reviewer queue. Reserve full human review for outputs above a defined risk threshold.
**Versioned audit trails** are what turn validation from a process into a record. Every validation decision, including the rationale and the model version that produced the output, should be logged in a versioned store. Public audit logs increase compliance confidence and give you a paper trail when something goes wrong.
> "Multi-model council certification includes parallel independent scoring of AI agents with public audit trails and automatic fail vetoes for transparency and reliability." — [dev.to/aetherneum](https://dev.to/aetherneum/we-built-a-4-model-council-to-certify-ai-agents-every-decision-is-in-git-3d6l)
**Automated veto systems** tied to synthetic transparency thresholds remove human bottlenecks from routine rejections while keeping humans in the loop for judgment calls. The combination is more reliable than either approach alone.
## Common mistakes and how to avoid them
These are the errors that show up repeatedly in pre-production AI testing pipelines.
- **Skipping semantic checks.** Schema validation passes, but the output contains a value that makes no business sense. Add semantic rules alongside your parser, not after it.
- **Confirmation bias in chain validation.** When a validator model sees the baseline output before scoring, [error detection drops](https://paulserban.eu/blog/post/chain-of-validation-engineering-reliable-ai-systems-through-iterative-self-verification/). Run validators independently without exposing them to the original response.
- **Static quality gates without risk context.** [Static rules fail](https://dev.to/waxell/ai-agent-output-validation-in-production-why-static-quality-gates-fail-and-how-to-fix-them-51ba) when they cannot account for operational risk. A rule that blocks low-confidence outputs unconditionally may halt a pipeline that should retry instead. Build in risk-context logic that decides between retry, escalate, and reject.
- **Incomplete policy specification.** A policy file with gaps is worse than no policy file. It gives false confidence. Audit your policy rules against your actual output types before going live.
- **Rolling out all validation layers at once.** Activate one contract layer at a time and monitor the failure rate. This tells you exactly which layer is catching which failures.
**Pro Tip:** *Risk-based validation scales effort to consequences. Apply formal inspections to self-learning systems and lighter checks to low-stakes decision-support tools. Not every model needs a council review.*
## My take on validation as a continuous practice
I've seen too many teams treat output validation as a checkbox. They build one schema validator, run it once before launch, and call it done. That approach works until the model drifts, the prompt changes, or a new data source introduces patterns the original rules never anticipated.
What actually works is treating [validation as an ongoing eval-to-guardrail practice](https://galileo.ai/blog/best-practices-for-ai-model-validation-in-machine-learning). The standards you define during development should become live enforcement rules in production. Not archived documentation. Not a one-time gate. Live rules.
The uncomfortable truth is that most model failures are quiet. They do not throw errors. They return plausible-looking output that is subtly wrong. A static schema check will not catch that. Semantic rules and multi-model review will, but only if you keep them current as the model evolves.
Risk context is what most teams leave out. High-risk AI systems need formal, documented [testing and audit readiness](https://sakaradigital.com/blog/risk-based-ai-validation-gxp/) similar to IQ/OQ/PQ in regulated industries. A decision-support tool used internally needs far less. The mistake is applying the same level of rigor to both, or worse, applying minimal rigor to everything because it feels like overhead. Versioned audit trails and transparent logging are not bureaucracy. They are what let you trust your own system.
> *— Gregory*
## Fix broken AI output before it reaches production
Datatool is built specifically for the broken, malformed, and schema-drifted output that LLMs produce in real pipelines. If your validation pipeline is surfacing truncated JSON, wrapped responses, or partial objects, Datatool handles the repair automatically.
[](https://datatool.dev/how-it-works/)
You can [fix broken JSON from AI](https://datatool.dev) and get clean, valid structured data back without manual debugging. Datatool detects invalid escaping, missing brackets, and schema drift across LLM outputs. It fits directly into your AI output testing workflow, handling the repair step that your schema validator flags but cannot fix on its own. Stop spending time hand-editing malformed responses. Let the tooling do it.
## FAQ
### What is a pre-production AI output validation setup?
A pre-production AI output validation setup is a pipeline of input, output, and error contracts that verify AI-generated structured data before it reaches production. It catches schema failures, semantic errors, and policy violations before they cause downstream damage.
### How do you validate AI outputs effectively?
Effective AI output validation combines schema parsing, semantic rule checks, and error routing. Structural validation alone is not enough. You need semantic checks that verify values are within allowed ranges and categories are valid, plus an error contract that routes failures to retry logic or alerts.
### What causes silent failures in AI pipelines?
Silent failures happen when validation only checks structure and ignores semantic logic. An output can be valid JSON and still contain a hallucinated category ID or an out-of-range confidence score that passes the parser and breaks downstream systems with no traceable error.
### When should you use human-in-the-loop validation?
Human-in-the-loop validation is necessary for high-risk or ambiguous outputs. It works best alongside automated layered validation, not as a standalone check. Route only outputs that exceed a defined risk threshold to human reviewers to keep the process efficient.
### What is the multi-model council approach?
The multi-model council approach runs an AI output through four independent reviewer models in parallel. Any output scoring below a synthetic transparency threshold of 9 out of 10 receives an automatic veto that human reviewers cannot override, increasing certification reliability.
## Recommended
- [Detect malformed output AI agents: a developer's guide](https://blog.datatool.dev/blog/detect-malformed-output-ai-agents-a-developers-guide)
- [AI output testing best practices for reliable structured data](https://blog.datatool.dev/blog/ai-output-testing-best-practices)
- [AI output observability explained: a developer's guide](https://blog.datatool.dev/blog/ai-output-observability-explained-a-developers-guide)
- [How to detect AI output errors for reliable structured data](https://blog.datatool.dev/blog/how-to-detect-ai-output-errors-for-reliable-structured-data)