
Understanding what is AI output determinism separates engineers who build reliable AI systems from those who chase unpredictable bugs across production. At its core, determinism in AI asks a simple question: given the same input, do you get the same output? The answer shapes everything from how you test, audit, and deploy AI models. Most developers assume modern large language models are purely non-deterministic by nature. That assumption leads to fragile architectures and failed pilots. This guide gives you the precise definitions, technical causes, and practical strategies you need to build AI systems you can actually trust.
Table of Contents
- Key takeaways
- What is AI output determinism
- Technical causes of AI output variability
- Testing and validating non-deterministic outputs
- Hybrid architecture: deterministic enforcement meets probabilistic generation
- My take on determinism in AI system design
- Fix AI output problems with Datatool
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Determinism vs. non-determinism | Deterministic AI returns identical outputs for identical inputs; non-deterministic AI varies by design. |
| Perfect determinism is impossible | Even at zero temperature, floating-point and GPU effects introduce variation in LLM outputs. |
| Traditional testing breaks | Exact-output assertions fail for AI; statistical and property-based validation methods are required. |
| Hybrid architectures work | Separating probabilistic generation from deterministic enforcement layers produces reliable, auditable systems. |
| Non-determinism is a feature | Variability in AI outputs enables reasoning and flexibility; the goal is control, not elimination. |
What is AI output determinism
At the most precise level, deterministic AI produces the exact same output for the same input every single time. Non-deterministic AI produces variable outputs based on statistical probabilities. These are not just academic distinctions. They define which tools you pick, which testing strategies apply, and which compliance frameworks you can satisfy.
Deterministic AI covers traditional rule-based systems, decision trees with fixed logic, and any model where the output is fully computable from the input without random sampling. SQL query engines, regex parsers, and most classical machine learning classifiers fall into this category. Given the same features and the same model weights, you get the same prediction. Always.
Non-deterministic AI introduces sampling. Modern large language models (LLMs) generate tokens by sampling from a probability distribution over the vocabulary at each step. That sampling process is inherently random unless you fully suppress it. Even when you suppress it, the randomness does not fully disappear.

Probabilistic AI is a subset of non-deterministic behavior where outputs vary according to learned statistical patterns. The term is often used to describe systems where the distribution of outputs is predictable even if individual outputs are not. Think of it as knowing the shape of the randomness without knowing each result.
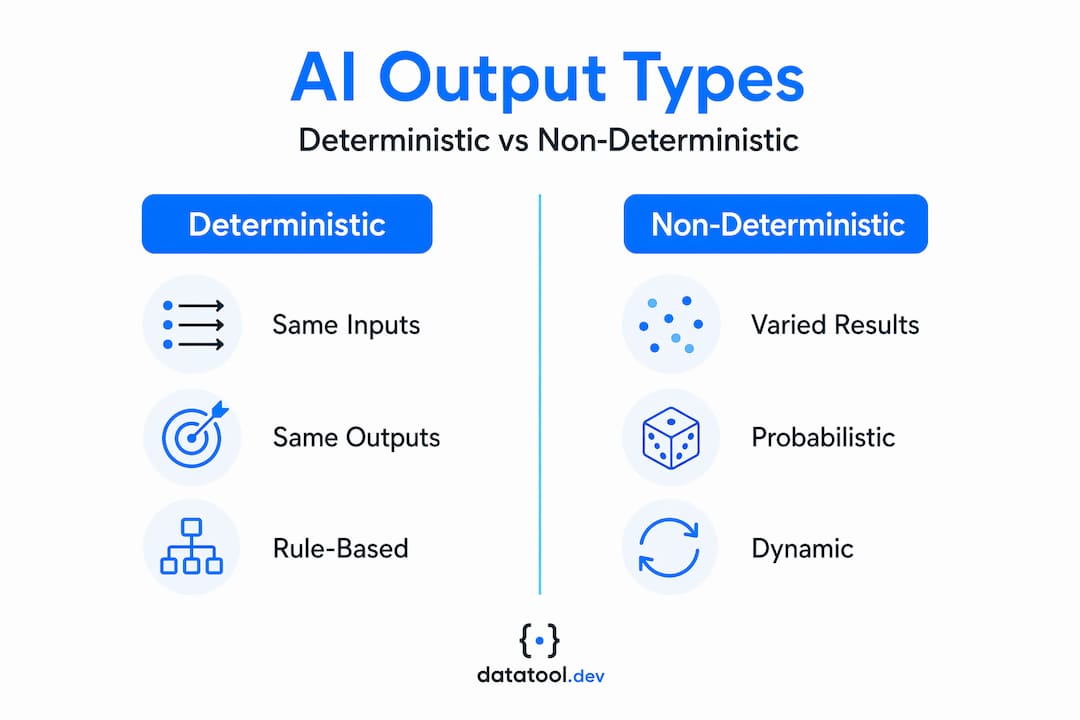
Here is a quick comparison to anchor the concepts:
| Characteristic | Deterministic AI | Non-deterministic AI | Probabilistic AI |
|---|---|---|---|
| Output for same input | Identical | Variable | Variable, but distribution-stable |
| Auditability | High | Low to medium | Medium |
| Compliance suitability | Strong | Weak without guardrails | Moderate with controls |
| Typical use case | Rules, logic, classifiers | Language generation, reasoning | Statistical prediction, generation |
| Testability | Exact assertions | Statistical validation | Distribution-based checks |
Technical causes of AI output variability
Understanding why AI outputs vary helps you design systems that account for it. Several layers of the stack contribute, and most engineers underestimate how many there are.
- Temperature and sampling parameters. Temperature controls how peaked the token probability distribution is. At temperature zero, the model always picks the highest-probability token. But temperature is only one variable. Top-p (nucleus sampling) and top-k sampling introduce further stochastic elements that clip or reshape the distribution before sampling occurs.
- Floating-point arithmetic and hardware effects. Even with temperature set to zero, GPU scheduling and floating-point precision cause non-deterministic output variations. Operations run in different orders across parallel threads. The rounding behavior of 32-bit floats accumulates differently depending on hardware load. No major provider guarantees fully deterministic outputs at the infrastructure level.
- Mixture-of-Experts (MoE) routing. Many frontier models use MoE architectures where different expert sub-networks activate for different inputs. The routing decision itself can be non-deterministic under parallel execution, meaning the same prompt may activate different experts under different load conditions.
- Batch-level dependencies. When your request shares a GPU batch with other requests, memory layout and computational order shift. The output you see in isolation may differ from the output you get under concurrent load.
- Context window state and KV cache behavior. Cached key-value states from prior context can be reused or invalidated differently depending on server-side caching policies. This is rarely documented but frequently affects reproducibility in production.
Pro Tip: Most engineers focus exclusively on setting temperature to zero and assume that solves determinism. It does not. The full determinism problem spans sampling parameters, hardware float precision, MoE routing, and infrastructure concurrency. Fix all layers, not just one.
The practical takeaway: design for inherent variability. Do not treat non-determinism as a bug to eliminate. Treat it as a constraint to engineer around.
Testing and validating non-deterministic outputs
95% of generative AI pilots fail because teams apply deterministic testing approaches to non-deterministic outputs. Exact-match assertions break the moment the model rephrases a response. You need a different testing philosophy entirely.
The right mental shift: you are not testing for a specific output. You are testing that the output satisfies a set of properties, regardless of how it is phrased. This is called property-based testing, and it is the foundation of reliable AI output validation.
Here is a stepwise approach to testing non-deterministic AI outputs:
- Define quality dimensions. Identify the dimensions that matter for your use case: accuracy, format compliance, tone, schema validity, and factual correctness. Score each dimension between 0 and 1 rather than treating output as pass/fail.
- Run multiple iterations per test case. A single-run test tells you almost nothing about a probabilistic system. Run each test case 10 to 30 times and compute aggregate scores. Statistical confidence matters more than individual results.
- Apply semantic similarity metrics. Use embedding-based comparison (cosine similarity against a reference answer) rather than string matching. Two outputs can be semantically identical and textually different.
- Validate schema and structure separately from content. A broken JSON wrapper and a factually wrong claim are different failure modes. Testing them separately gives you cleaner signal on where failures originate. Datatool's resources on AI output testing cover this distinction in depth.
- Build regression suites from real failures. Collect examples of malformed, truncated, or schema-violating outputs from production. Add them to your test suite. Real failures are more informative than synthetic edge cases.
- Set risk-adjusted thresholds. A compliance-sensitive pipeline might require a 0.98 schema-compliance score across 30 runs. A creative content workflow might accept 0.85. Thresholds should match your risk tolerance, not an arbitrary standard.
For agentic systems, the stakes rise further. Error rates around 5% in LLM outputs require constant monitoring and fallback mechanisms to prevent cascading failures across multi-step pipelines. Human-in-the-loop controls at decision boundaries are not optional. They are load-bearing architecture.
Check out Datatool's guide on detecting AI output errors for a practical framework on identifying structural failures before they reach your application layer.
Hybrid architecture: deterministic enforcement meets probabilistic generation
The best production AI systems do not choose between determinism and non-determinism. They architect both, explicitly, with clear boundaries between them. Hybrid AI workflows combine probabilistic models for interpretation with deterministic orchestration that enforces consistent execution.
The pattern is: the LLM generates, a deterministic layer validates. The LLM reasons about intent or extracts meaning from unstructured input. A downstream enforcement layer applies schema checks, business rules, compliance constraints, and output sanitization before the result propagates. Separating generation from validation architecturally is recognized as best practice precisely because it contains variability where it belongs.
Practical scenarios where this matters most:
- Compliance-sensitive workflows. Deterministic AI ensures auditability under SOC 2, PCI-DSS, and HIPAA frameworks by producing reproducible outputs at the enforcement layer. The LLM extracts relevant data; deterministic logic handles the decision.
- Security pipelines. Non-deterministic AI is useful for detecting anomalies and interpreting threat signals. Deterministic rules govern the response actions: block, alert, escalate. Mixing the two without a hard boundary creates audit nightmares.
- Data extraction and structured output generation. The LLM parses unstructured text into candidate structured data. A schema validator, running deterministic checks, confirms the output before it enters your database. If the schema check fails, you repair or retry, not propagate.
Architectural pitfalls to avoid:
- Do not let LLM output flow directly into business logic without a validation layer. The output will eventually be malformed.
- Do not rely on prompt engineering alone to enforce schema compliance. Prompts drift. Schema validators do not.
- Do not conflate temperature zero with determinism. As covered earlier, infrastructure variability persists regardless of sampling settings.
- Do not skip confidence scoring. Confidence scores and fallback triggers are what separate production-grade AI systems from demos.
Non-deterministic outputs are a feature, not a flaw, when constrained within deterministic guardrails. The goal is not to eliminate variability. It is to contain it.
My take on determinism in AI system design
I've spent a significant amount of time watching teams make the same architectural mistake: they treat non-determinism as the enemy and try to engineer it away completely. That instinct is understandable. It is also wrong.
What I've learned is that non-determinism is where LLMs earn their value. The ability to reason across ambiguous, unstructured inputs, to interpret intent rather than match patterns, requires sampling from a distribution. Kill that, and you get a worse, slower, more expensive rule engine.
The real work is building the deterministic layer around the probabilistic core. In my experience, teams that invest in robust schema validation, output repair pipelines, and confidence-scored fallbacks end up with systems that are more reliable than teams chasing temperature-zero perfection. The former accept variability and design around it. The latter keep adding prompt constraints until the system is brittle and unmaintainable.
Testing is where I see the most pain. Moving from exact assertions to statistical quality scoring feels uncomfortable at first. It requires you to redefine what "passing" means. But once you do, you can actually ship AI features with confidence rather than hoping the output holds on the next run.
The future I expect to see: deterministic enforcement tooling becomes a standard layer in every AI pipeline, the same way linters and type checkers became standard in software development. We are early. But the direction is clear.
— Gregory
Fix AI output problems with Datatool
When you build on top of probabilistic AI, malformed outputs are not hypothetical. They happen. Broken JSON, truncated responses, schema drift, invalid escaping. These are daily realities for any team working with LLM-generated structured data.
Datatool repairs and validates AI-generated structured data built for exactly these failure modes. Whether you are dealing with wrapped responses, partial objects, or outputs that drift from your schema under load, Datatool gives you the repair and validation layer your AI pipeline needs. It is designed for developers who need AI output reliability without rebuilding their entire architecture. Reduce risk. Trust your data.
FAQ
What is AI output determinism?
AI output determinism means a model produces the same output every time it receives the same input. Deterministic AI systems are essential for compliance, auditability, and reproducible testing.
Why are LLM outputs non-deterministic even at zero temperature?
Even with temperature set to zero, floating-point precision and GPU parallelism cause variation in LLM outputs. No major provider guarantees bit-perfect determinism across runs.
How do you test non-deterministic AI outputs reliably?
Replace exact-match assertions with property-based testing and statistical validation. Score quality dimensions like format, accuracy, and tone across multiple iterations rather than asserting a single expected result.
When should I use deterministic vs. non-deterministic AI?
Use deterministic AI for compliance workflows, decision execution, and auditable processes. Use non-deterministic AI for interpretation, language generation, and reasoning tasks where flexibility improves accuracy.
What is a hybrid AI architecture?
A hybrid architecture pairs a probabilistic LLM for generation and interpretation with a deterministic enforcement layer that validates schema, applies business rules, and handles execution. This is the recommended pattern for production AI systems.