
Structured output AI is a technique that forces a language model to generate responses that conform exactly to a developer-defined JSON schema, guaranteed at the token level. Unlike asking an LLM to "reply in JSON," which succeeds only 80-90% of the time, structured output uses constrained decoding to make schema violations impossible. OpenAI's Strict Mode, Pydantic model definitions, and JSON Schema are the primary tools developers use to implement this today. The result is machine-readable data you can trust without writing a single regex parser or retry loop.
What is structured output AI and how does it differ from JSON mode?
Structured output AI enforces a predefined schema at generation time, not after the fact. The model cannot produce a response that violates the schema because invalid tokens are masked before they can be selected. This is the technical guarantee that separates it from every other approach.
JSON mode, by contrast, guarantees parseable JSON but nothing more. The model can return valid JSON that is missing required fields, uses the wrong types, or includes unexpected keys. Your downstream code still breaks. Structured output with strict mode eliminates that entire class of failure.

Prompt engineering is even less reliable. Asking a model to "return a JSON object with fields name, age, and status" works well in demos and fails in production. Complex or nested schemas make prompt-based approaches worse. The 80-90% success rate for prompt-based JSON requests sounds acceptable until you are running thousands of requests per day and debugging the 10-20% that silently corrupt your pipeline.
The industry term for this capability is constrained decoding or schema-constrained generation. "Structured output" is the product-level name OpenAI uses, but the underlying mechanism is the same across implementations.
How does constrained decoding actually work?
The mechanism behind structured output is a finite state machine compiled from your schema. At each decoding step, the model's token vocabulary is filtered to include only tokens that keep the output on a valid path through that state machine. Tokens that would violate the schema are masked to zero probability before sampling occurs.
Here is what that means in practice:
- Schema compilation: Your JSON Schema or Pydantic model is compiled into a finite state machine at request time. This introduces a 50-200ms latency cost on the first request. Subsequent requests use a cached version, so the cost disappears.
- Token masking: At every generation step, only tokens consistent with the current state are allowed. The model cannot produce a string where an integer is required.
- 100% compliance: The output is guaranteed to match your schema's fields, types, required properties, and enum values. No exceptions.
Pro Tip: Define your schema once as a Pydantic model and use it as the source of truth for both the API call and your downstream validation. This eliminates schema drift between your request and your parsing code.
The performance cost is worth it. A 50-200ms overhead on first request is a small price for eliminating on-call incidents caused by malformed AI output. The tradeoff favors production reliability in every real-world scenario Datatool has observed.
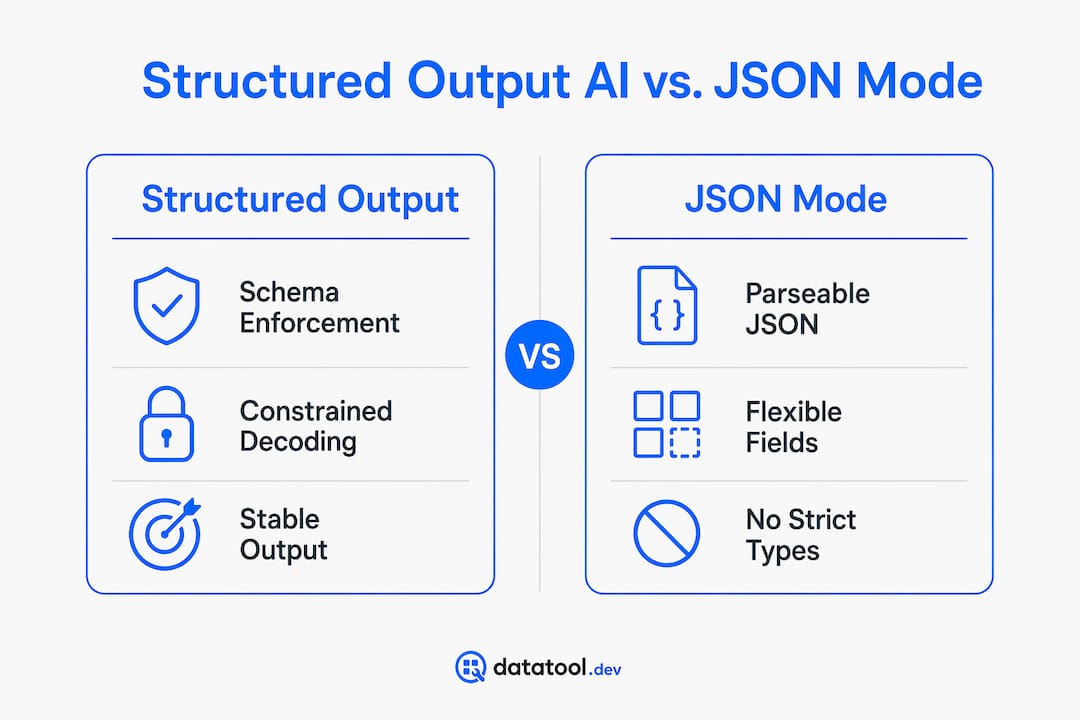
What are the benefits and limitations of structured output AI?
The core benefit is predictability. Your AI pipeline produces data in a known format, every time. This removes an entire category of bugs from your codebase and lets you detect AI output errors before they reach production systems.
Specific benefits for developers and data scientists:
- No fragile regex parsers or retry loops in your codebase
- Reliable extraction, classification, and summarization workflows
- Complex schemas with required fields, typed arrays, and enums all enforced
- Reduced maintenance overhead across AI-powered data pipelines
The limitations are equally important to understand. Structured output only guarantees format correctness, not factual accuracy. A model can return a perfectly valid JSON object where every field contains a hallucinated value. The schema enforces structure. It does not enforce truth.
Structured output solves the format problem. It does not solve the truth problem. Semantic validation is not optional in production.
Schema design quality also matters more than most developers expect. Overly loose schemas with broad field types and no enums produce poor data quality even when schema conformance is technically 100%. A field typed as "string` with no pattern constraint gives the model too much freedom. Use enums, patterns, and length constraints wherever the domain allows it.
Finally, strict mode cannot prevent refusals. A model can return an empty stub or a refusal response that is technically schema-valid. Explicit refusal detection and semantic validation must sit between your schema check and your business logic. Treat schema conformance as a necessary condition, not a sufficient one.
How to implement structured output AI with real code
Implementation follows four steps. Get each one right and your pipeline is solid.
- Define your schema. Use a Pydantic model or a JSON Schema object. Pydantic is preferred in Python because it gives you type safety on both sides of the API call.
- Pass the schema with strict mode enabled. In the OpenAI Python SDK, set
response_formatto your schema andstrict=True. This activates constrained decoding. - Parse and validate the response. Libraries like
instructorin Python remove the need for brittle parsing by handling deserialization directly into your Pydantic model. - Check for refusals and run semantic validation. Before passing data downstream, verify that required fields are non-empty and that values make sense in context.
Here is a minimal example showing the failure case and the fix:
Without structured output (breaks in production):
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Extract name and age as JSON"}]
)
data = json.loads(response.choices[0].message.content) # Fails ~10-20% of the time
With structured output (100% schema compliance):
from pydantic import BaseModel
class Person(BaseModel):
name: str
age: int
response = client.beta.chat.completions.parse(
model="gpt-4o",
messages=[{"role": "user", "content": "Extract name and age"}],
response_format=Person,
)
person = response.choices[0].message.parsed # Always a valid Person object
Pro Tip: Always check response.choices[0].message.refusal before accessing .parsed. A non-null refusal means the model declined to answer. Your code must handle this branch explicitly or you will get silent failures.
Datatool's AI output testing practices recommend treating every structured output response as untrusted until semantic validation passes, regardless of schema conformance.
Structured output vs. JSON mode vs. function calling
These three approaches are not interchangeable. Each solves a different problem.
| Approach | What it guarantees | Best use case |
|---|---|---|
| Prompt-based JSON | Nothing formally | Prototyping only |
| JSON mode | Syntactically valid JSON | Simple, flat responses |
| Structured output | Full schema conformance | Production extraction and classification |
| Function calling | Tool invocation and orchestration | Agents and multi-step workflows |
Structured outputs work best for extraction, classification, and summarization workflows that need a stable machine-readable contract. Function calling handles orchestration: deciding which tool to call and with what arguments. Many production systems use both. Structured output defines the data contract. Function calling manages the workflow around it.
The benefits of AI output constraints compound over time. Teams that adopt structured output early spend less time debugging AI pipeline failures and more time building features.
Key takeaways
Structured output AI guarantees schema-level format compliance through constrained decoding, but semantic validation and refusal handling remain required for production reliability.
| Point | Details |
|---|---|
| Constrained decoding is the mechanism | Token masking at generation time enforces 100% schema compliance, unlike prompt-based approaches. |
| JSON mode is not structured output | JSON mode guarantees parseable JSON only; structured output enforces fields, types, and enums. |
| Format is not truth | Hallucinations remain possible inside a valid schema; semantic validation is always required. |
| Schema quality determines output quality | Use enums, patterns, and length constraints to get reliable values, not just valid structure. |
| Refusal handling is mandatory | Strict mode cannot prevent empty stubs or refusals; check the refusal field before trusting data. |
Why I stopped treating schema conformance as the finish line
I have reviewed a lot of AI pipelines that broke in production despite using structured output correctly. The pattern is almost always the same: the team treated schema conformance as the end of the validation story. It is not. It is the beginning.
Regex-based output corrections and retry loops are a sign that something upstream is wrong. They are not a solution. Moving to native constrained decoding fixes the format problem permanently. But I have seen teams make that migration and then ship hallucinated data into critical systems because they assumed a valid schema meant valid data.
The teams that get this right build two distinct validation layers. The first is schema conformance, handled by structured output. The second is semantic validation: does this value make sense given the context? Is this classification consistent with the input? Is this extracted date actually in the past? Those checks cannot be automated away. They require domain knowledge and deliberate engineering.
The latency cost of structured output is real but small. The maintenance cost of not using it is large and ongoing. That tradeoff is not close.
— Gregory
Fix and validate your AI JSON output with Datatool

Even with structured output enabled, real-world LLM responses produce malformed JSON. Truncated objects, broken escaping, schema drift across model versions, and partial outputs are all common failure modes in production pipelines. Datatool is built specifically for these problems. It repairs broken JSON, validates against your schema, and flags semantic issues before they reach your application logic. If you are building AI-powered data pipelines and need to fix broken JSON from AI, Datatool gives you the tools to do it reliably. Paste malformed output. Get valid, schema-conformant JSON back.
FAQ
What is structured output AI in simple terms?
Structured output AI forces a language model to return responses that match a predefined JSON schema exactly, using constrained decoding to make schema violations impossible at generation time.
How is structured output different from JSON mode?
JSON mode guarantees syntactically valid JSON but does not enforce specific fields, types, or required properties. Structured output with strict mode enforces the full schema, including field names, data types, and enum values.
Can structured output prevent hallucinations?
No. Structured output only guarantees format correctness, not factual accuracy. A model can return a perfectly valid JSON object containing hallucinated values. Semantic validation is still required.
Does structured output add latency?
Yes, but minimally. Schema compilation into a finite state machine adds 50-200ms on the first request. Subsequent requests use a cached version and the overhead disappears.
When should I use function calling instead of structured output?
Use structured output for extraction, classification, and summarization workflows. Use function calling for orchestration and tool invocation in agent workflows. Many production systems use both together.